
Product Excellence Through Modern PLM in Fast-Paced Markets
Modern PLM systems empower businesses to achieve product excellence in fast-paced markets by enhancing collaboration, agility and innovation.

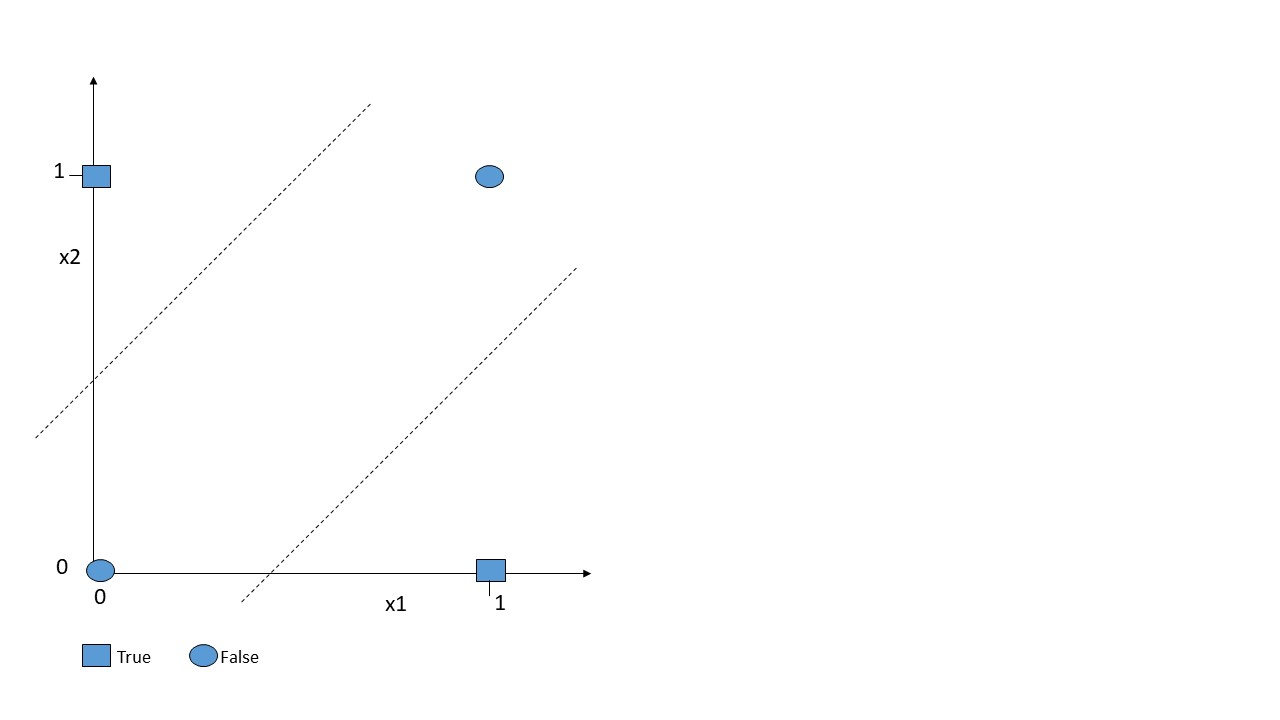
The XOR problem is the simplest problem a perceptron is not able to solve. Given two inputs, the XOR problem means that a neuron is true only if the inputs from previous neurons are not the same.
Hence, it is true given {(1,0), {0,1)}, but not for {(0,0), (1,1)}. If we depict this problem in two-dimensional space as in Figure 1, it becomes obvious that it can’t be solved with a single line, since we are not able to separate true and false data points with a single line.
However, inserting another hidden layer between the input and output layers solves the problem. We introduce a single hidden layer consisting of two neurons that are connected to each neuron of the previous input and the successive output layers, as displayed in Figure 2. Remember that each neuron has a weight and bias attached to it, which might be initialized randomly or according to some probabilistic distribution. The output at the hidden layers H1 and H2 will be calculated as follows:
First, the weighted sum of the inputs that reach the hidden unit is calculated. Then, this sum is provided as an input to a non-linear activation function. An activation function defines how the weighted sum of the inputs is transformed into an output. In this case, we choose the sigmoid function as activation at both the hidden and output layers. The sigmoid function is an S-shaped curve that squashes any real value between 0 and 1. If the outcome of the sigmoid function is greater or equal to 0.5, we classify that node as class 1 and let the signal pass and if it is less than 0.5, we classify it as class 0 and the signal stops.
Finally, the function for the output node is as follows:
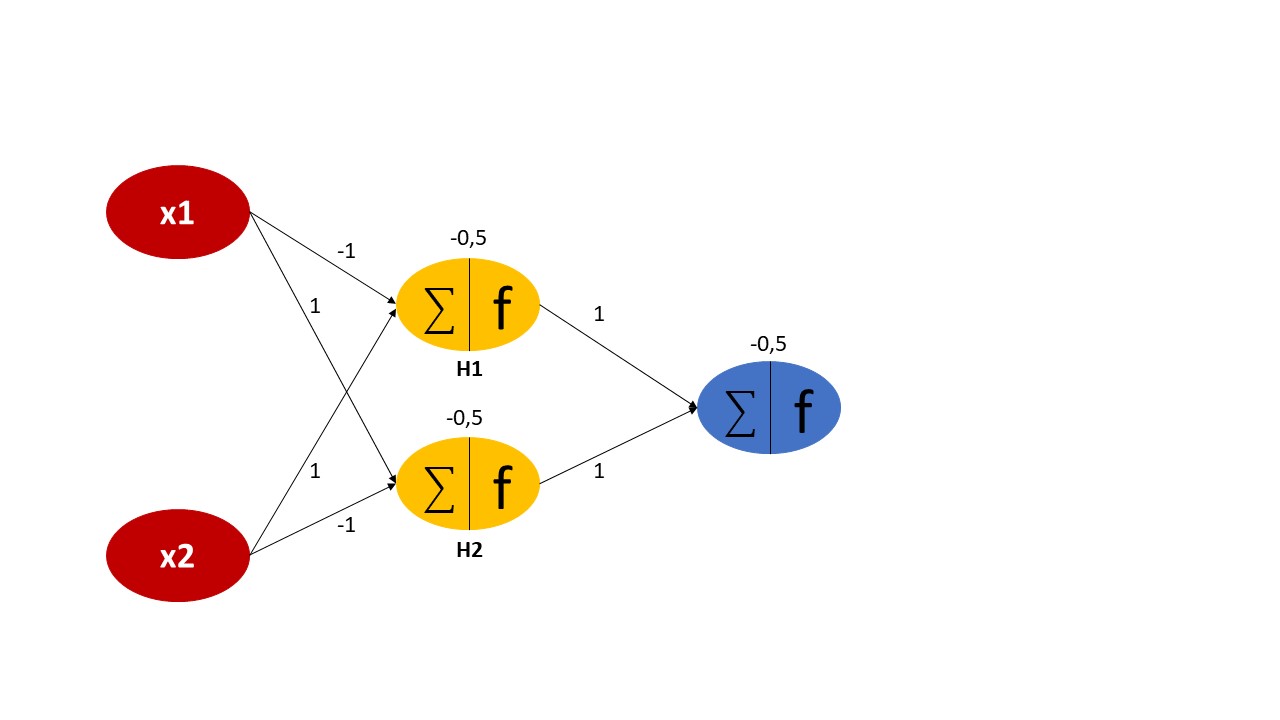
If you solve that network with all combinations of {(0,0), (0,1), (1,0), (1,1)}, you will see that the output is true for (0,1) and (1,0), but false for (0,0) and (1,1). Or in other words, the network solves the XOR problem. In this example case, the weights and biases were set in a way that the problem got solved right away. For real-world problems this is usually not the case. Here, the network needs to “learn” those parameters by repeatedly being exposed to the input data and adjusting the weights in a way to get closer to the expected output. This process of calibrating the network is called backpropagation.
Modern PLM systems empower businesses to achieve product excellence in fast-paced markets by enhancing collaboration, agility and innovation.

Read how the Campaign Planner & Designer (CPD) helps you to manage supply chain variability.

Explore automated production planning with our Campaign Planner & Designer.

The pharma market trends impact logistics with a shift to smaller, higher-value shipments and new temperature requirements.
